写这篇文章的原因主要是因为在C语言学习社群中发现同学们对于数组的理解还不够深刻,没有与内存地址和指针相结合去理解。在阅读本文前需已学习指针相关知识。
本篇文章将对C语言数组进行剖析,以一维数组和二维数组为例子,N维数组可同理类比,打通C语言数组学习的任督二脉。相信同学们在阅读和理解本篇文章内容后,会对数组的存在有着更为深刻理解。
这篇文章主要分为以下两个个部分:
- 数组在内存空间的存在形式
- 数组名与指针的关系和区别
数组在内存空间的存在形式
我们定义一个数组,需要指明数组的元素个数,即数组的大小。在编译运行时,程序会在内存的栈区开辟一块连续的内存空间给数组。假设我们定义一个数组char a[6],那么其在内存空间中的存在形式如下示意图
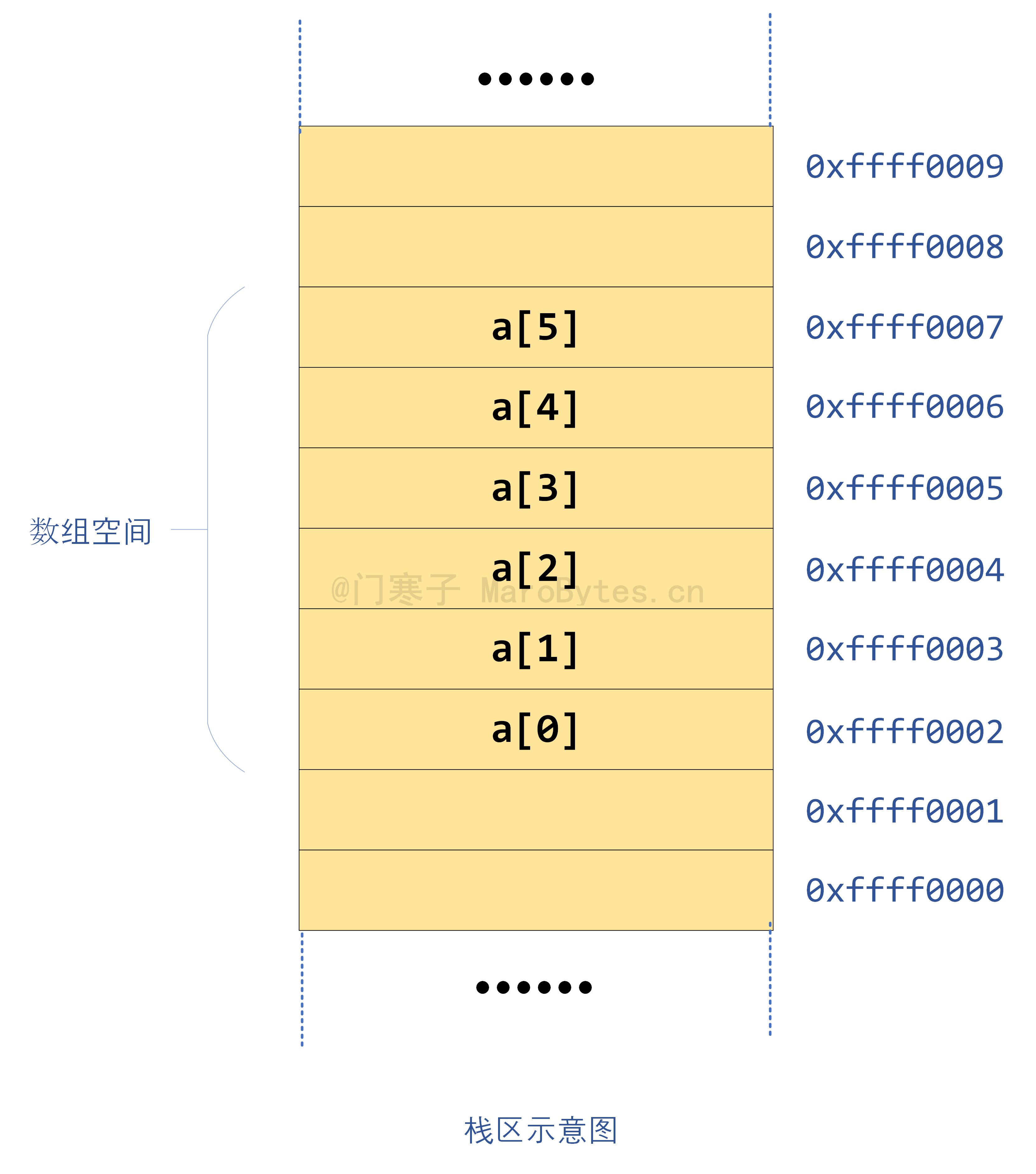
编译器从0xffff0009地址处开始向下分配空间,数组大小有6个char类型的元素,每个char类型占据1字节空间,所以数组占据的是从0xffff0007到0xffff0002的连续内存空间地址。
#include <stdio.h>
#define MAX 10
int main()
{
char a[MAX];
/*......*/
return 0;
}在定义一个数组时,习惯性使用宏定义一个常量,这样做方便直接修改数组元素的个数,同时也要多加上少量的元素个数,这种做法能够在一定程度上避免数组越界,例如我们将MAX设为10。
由于栈区所能分配的内存空间并不是很大,在定义一个超长数组时,很容易发生栈溢出(Stack OverFlow)错误,导致程序崩溃。这时我们可以考虑使用动态内存函数malloc()或者calloc(),动态内存函数是在堆区上分配空间,且可以根据需要通过realloc()函数增加内存空间,既能够按需分配空间,也可以有效缓解栈区上内存空间不足的问题。
当然,在日常学习中,我们可能很少会遇到需要你定义一个1000000000000个甚至更多个元素的数组(不排除出题者故意考验你的情况)。
数组名与指针的关系和区别
有很多同学,甚至是某些参考书认为,数组名就是指针。这种理解方式实际上是错误的!刚入门学习C语言的同学,一定要区分开数组名和指针的概念,万万不能简单的将两者等价起来。
指针也称指针变量,是用来存放内存地址的变量,有着相应的指针类型。
数组名是数组首元素的地址(此处的首元素在不同维的数组中的理解不同),但是有两个例外:
sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小&数组名,这里的数组名表示整个数组,取出的是整个数组的大小
数组名与指针类似,都存放着内存地址,也能够进行解引用操作,以及直接利用数组名进行加减运算(类比于指针的加减运算)。我们可以与之类比,但数组名绝不是指针。
我们不能改变数组名中存放的地址,且其所表示的访问权限(访问多少个字节的内存)在不同情况下会有所差异。正确的理解应该如上述,数组名为首元素的地址,这将更好的帮助我们从内存角度理解数组。
以下我们从一维数组和二维数组进行举例说明
一维数组
假设我们定义一个一维数组int a[6],其示意图如下

数组名a表示首元素地址,即a[0]的地址,但在例外情况下,它代表的是整个数组的地址。通过以下代码运行可得到,它们存放的地址一致,但访问权限不一致。&a代表整个数组,访问权限即为一个数组的长度,a表示首元素地址,访问权限为int类型的字节大小。
#include <stdio.h>
int main()
{
int a[6] = {0};
printf("%p\n", a);
printf("%p\n", &a);
printf("%p\n", a + 1);
printf("%p\n", &a + 1);
return 0;
}我们注意到,&a + 1所指向的内存地址是整个数组后的内存地址,而a + 1的所指向的内存地址则与a[1]的内存地址相同。*(a + 1)就是等于a[1],[]符号其实就可以改写成*()的形式,其中括号内是[]内外数组名和下标相加。
不要忘了[]其实也是个运算符噢,理解了这个概念,事实上我们可以将数组名和下标位置对调,写成如下形式,这两种写法在语法上是没有毛病的,你可以自己尝试编译运行。
printf("%d", 2[a]);
printf("%d", a[2]);
//我们通常使用第2种写法,第一种写法你可以炫技,但请不要用于正式编程中二维数组
假设我们定义一个一维数组int a[2][6],其示意图如下
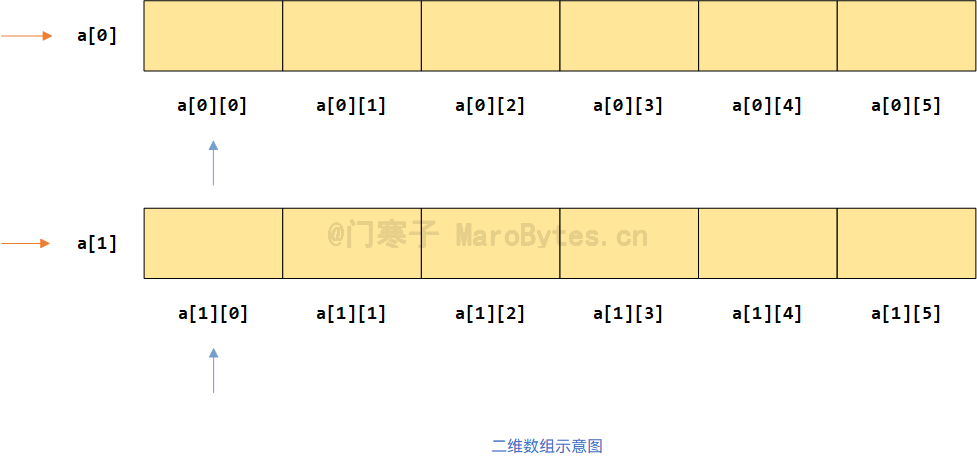
此时,在二维数组中,看作是有两个一维数组的元素,它们的内存空间是连续的。数组名表示的是第一个一维数组的内存地址。我们可以将a[0]和a[1]看作是这两个一维数组的数组名。
a即表示a[0],我们要特别注意的是不同的表示形式,所带来的访问权限也不同。我们在一维数组中可以以*a的形式解引用第一个元素,但不能在二维数组中以该形式解引用,原因可想而知,我们不能解引用整个一维数组。
我们通过例子来进行理解
#include <stdio.h>
int main()
{
int a[2][6] = { { 1,2,3 }, { 4,5,6 } };
printf("%d\n", *(*(a + 1))); // 输出4
printf("%d\n", *(a + 1)); // 输出随机值
return 0;
}根据[]运算符的改写形式,我们可以将上面两个例子改写成a[1][0]和a[1],这样是不是更好理解了。详细的改写步骤如下
- 第一步:
a + 1表示在二维数组层面,地址由首行变为第二行,示意图中由黄色指针进行变动 - 第二步:
*(a + 1)表示进入一维数组层面,理解为a[1],因为它解引用是解出第二行整行的数组,示意图中黄色指针变为蓝色指针 - 第三步:
*(*(a + 1))相当于*(*(a + 1) + 0),理解为a[1][0],即解出第二行第一个元素
数组传参
我们既然知道了一维数组的数组名表示首元素的地址,且数组名能够进行加减运算,那么在进行函数传参的时候我们可以写成以下两种形式。通常情况,我们不能只传数组,还需要把数组元素个数一起传入,否则函数并不知道该数组有多大,没有访问终止界限。
// 指针形式
void function(int *a, int size);
// 数组形式
void function(int a[], int size);// 括号内的数字可写可不写,因为无意义,传的是首元素地址二维数组的传参同理也可以写成以下两种形式,特别注意必须要写上列数,否则程序运行时将无法判断一行的终止界限。其指针形式也可以理解成是数组指针,a是一个指针,指向int类型的数组,数组有6个元素,这与我们将二维数组看作是存放一维数组的理解是一致的。
// 指针形式
void function(int (*a)[6]);
// 数组形式
void function(int a[][6]);